https://www.slideshare.net/Amr_abd_ellatief/test-vector-compression
Test vector compression
Test vector compression - Download as a PDF or view online for free
www.slideshare.net
SoC 테스트를 위한 테스트 데이터 압축방법
http://soc.yonsei.ac.kr/Abstract/International_journal/IDEC133.pdf
Survey of VLSI Test Data Compression Methods
https://core.ac.uk/download/pdf/228971691.pdf
위의 PPT와 PDF에서 나온 Test vector compression에 대해 정리해보자.

칩의 한 부분이 고장 나면 옆 부분도 영향을 받을 수 있어 테스트 데이터가 비슷한 패턴을 가진다. 또 test vectors 중 1~5%만 specified bit이고 나머지는 don’t-care라고 한다.
The Compression Technique Categories
지금 살펴볼 Test vector compression의 기법은 다음과 같다
1. CODE BASED TEST DATA COMPRESSION TECHNIQUES
- Run-length based codes
- Dictionary codes
- Statistical codes (Huffman coding),
2. LINEAR-DECOMPRESSION-BASED SCHEMES
3. BROADCAST-SCAN-BASED SCHEMES
4. Geometric methods
Run-length based codes
위의 Data stream을 보면 0의 개수를 Run length로 표기한 것을 알 수 있다. Encoded data는 각 Run length를 나타내고 있다. 01은 1, 1000은 2비트씩 끊어서 생각하면 2이고 1010또한 2비트씩 끊어서 더하면 4, 110010은 3비트씩 끊어서 더하면 8이 된다.
Dictionary codes
위를 보면 더 잘 이해가 되는데, 약간의 변형된 Hash table형식이라 이해할 수 있다. complete dictionary를 사용하면 b bit의 입력으로 n bit의 스캔 체인에 입력이 된다.
Statistical codes (Huffman coding)
과정이 끝난 뒤에는 Huffman tree가 만들어 지는데 각 symbol의 노드 위치에 따라 Huffman Code가 정해지게 된다.
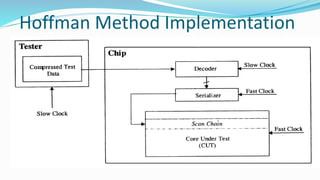
- Tester에서 Compressed Test Data가 Slow Clock으로 Chip의 Decoder로 전송된다.
- Decoder는 데이터를 복원하고 Serializer는 데이터를 직렬화하여 Scan Chain으로 보낸다.
- Scan Chain은 데이터를 Core Under Test (CUT)에 입력하여 테스트를 수행한다.
Linear decompression
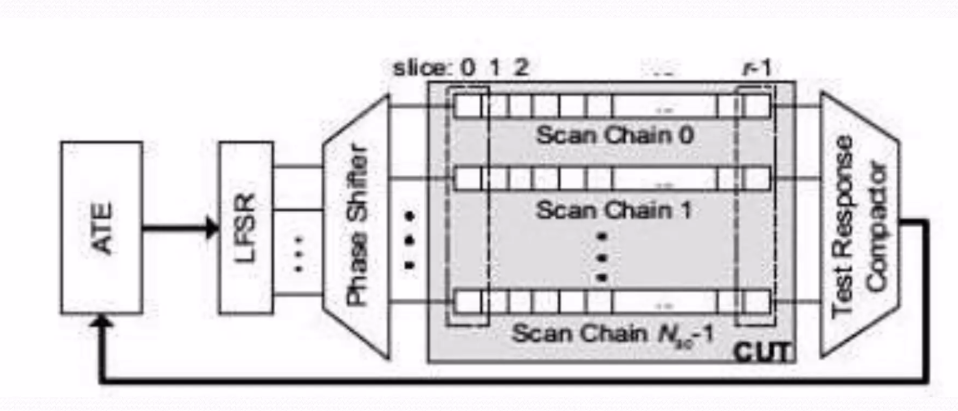
Linear Decompression의 압축과 복원
Encoding
Linear Decompression에서 압축은 test cube를 free variable(자유 변수)로 변환하는 과정이다. 테스트 큐브는 don’t-cares(X)가 포함된 테스트 패턴이다. free variable은 ATE에서 제공되는 비트로, 0 또는 1로 설정할 수 있는 값이다. 다이어그램에서 free variables는 ATE가 LFSR에 제공하는 seed이다. 압축은 테스트 큐브를 생성할 수 있는 free variable을 계산하는 과정이다.
인코딩은 테스트 큐브의 specified bit(0 또는 1로 고정된 비트)에 맞는 free variable을 계산하는 과정이다. 이를 위해 선형 방정식 시스템 AX = Y를 푼다. 예를 들어, 테스트 큐브 01X0에서 specified bits는 0(첫 번째 비트), 1(두 번째 비트), 0(네 번째 비트)이다. characteristic matrix A가 다음과 같다고 가정해보자.
- 첫 번째 비트: X1 + X2 = 0
- 두 번째 비트: X2 + X3 = 1
- 네 번째 비트: X3 + X4 = 0
(여기서 +는 XOR 연산이다.) 이 방정식을 풀면 X1=0, X2=1, X3=0, X4=0이 해가 될 수 있다. 이 free variables(X1, X2, X3, X4)가 ATE에 저장된다. 이 과정이 압축(인코딩)이다.
인코딩을 통해 계산된 free variable은 ATE에 저장된다. 1000비트 테스트 큐브를 생성하기 위해 10비트 free variable이 계산되면 ATE는 이 10비트만 저장한다.
Decoding
위의 다이어그램(ATE, LFSR, Phase Shifter, Scan Chains, CUT, Test Response Compactor)을 봐보자. ATE는 free variable(seed)를 LFSR에 제공한다. LFSR은 seed를 받아 테스트 데이터 스트림을 생성한다. 만약 10비트seed(1010101010)를 LFSR이 받으면, LFSR은 피드백 다항식에 따라 10101010 → 01010101 같은 스트림을 생성한다. Phase Shifter는 이 데이터를 여러 scan chain으로 분배하며 상관관계를 줄이기 위해 데이터를 섞는다.
Scan Chains는 Linear Decompressor(LFSR과 Phase Shifter)에서 생성된 테스트 데이터를 받아 CUT(Core Under Test)에 적용한다. 다이어그램에는 Scan Chain 0, Scan Chain 1, ..., Scan Chain Nc-까지 Nc개의 scan chain이 있다. 각 scan chain은 플립플롭으로 구성되어 있으며, 데이터를 한 비트씩 이동시킨다. . 모든 slice가 채워지면 scan chain의 데이터가 CUT에 적용된다.
Test Response Compactor는 테스트 결과를 압축한다. Scan Chain에서 나온 테스트 결과는 데이터 크기가 크다. 예를 들어, 10개의 scan chain이 각각 100비트 결과를 출력하면 총 1000비트 데이터가 된다. Test Response Compactor는 이 데이터를 10비트 시그니처로 압축하여 ATE로 보낸다. 이 시그니처는 ATE에서 분석되어 결함 여부를 판단한다.
Linear Decompression의 유형
Static reseeding은 각 테스트 큐브마다 free variable(seed)를 계산하는 방식이다. LFSR은 seed를 받아 테스트 벡터를 생성한다. 100비트 테스트 벡터를 생성하려면 LFSR이 100 클럭 동안 데이터를 생성한다. 이 동안 회로가 idle 상태(테스트가 멈춘 상태)에 있어 테스트 시간이 늘어난다. 또한, LFSR의 크기가 테스트 벡터 길이만큼 커야 하므로 하드웨어 비용이 증가한다. 하지만 ATE는 seed만 저장하면 되므로 메모리 사용량이 줄어든다.
Dynamic reseeding은 Static reseeding의 단점을 해결하는 방식이다. 네트워크(ex) Phase Shifter)를 사용해 LFSR의 출력을 여러 scan chain으로 확장한다. 다이어그램에서 Phase Shifter가 LFSR의 출력을 여러 scan chain으로 분배하는 모습은 Dynamic reseeding에 해당한다. Dynamic reseeding은 LFSR의 크기를 줄이고, 회로가 idle 상태에 머무는 시간을 단축한다.
Broadcast Scan Method
Broadcast Scan Method 기반 압축은 don’t care bit를 활용하여 테스트 패턴 수를 줄이고 여러 scan chain에 데이터를 분배한다. Don’t care bit는 테스트 결과에 영향을 주지 않는다. 이 기법은 Independent와 Dependent 두 가지 유형으로 나뉜다.
Independent Broadcast Scan Method는 각 회로(CUT, Circuit Under Test)에 독립적으로 ATPG(Automatic Test Pattern Generation)를 적용하여 테스트 패턴을 생성하고, don’t care bit를 활용하여 fault를 동시에 검출한다. 예를 들어, 스마트폰 칩의 CUT-1(이미지 처리 회로)과 CUT-2(Wi-Fi 데이터 전송 회로)에 대해 ATPG가 각각 패턴 1010XX0X와 XX10X01X를 생성했다고 하자. Don’t care bit를 활용하여 이 패턴을 1010100X로 병합하면, 단일 패턴으로 두 회로의 결함을 검출할 수 있다. 이는 테스트 패턴 수를 줄여 ATE의 메모리 사용량을 줄이고 테스트 시간을 단축한다.
Dependent Broadcast Scan Method는 Illinois scan based compression technique을 사용하여 테스트 데이터를 분할(partition)하고, Broadcast(병렬) 또는 Serial(직렬) 모드로 적용한다.
Illinois Scan의 세부 동작과 Linear Decompression과의 관계
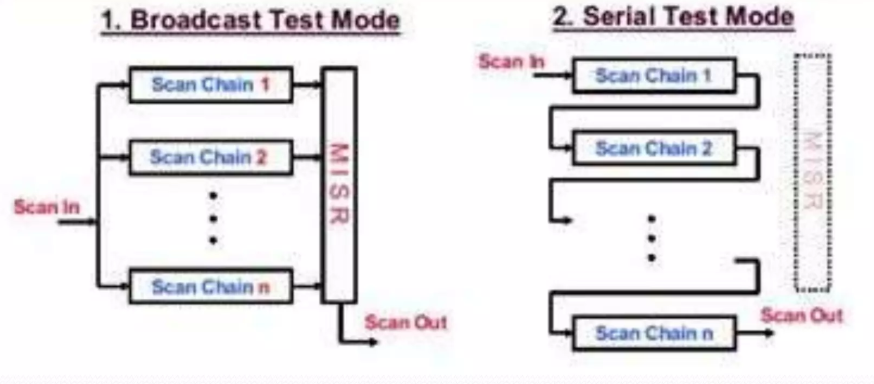
Illinois scan은 Dependent Broadcast Scan Method의 핵심으로 테스트 데이터를 압축하고 scan chain에서 같은 셀이 반복되는 문제를 피한다. Illinois scan은 multiplexer를 사용하여 테스터 채널이 어떤 scan chain에 데이터를 broadcast할지 선택하며, static reconfiguration과 dynamic reconfiguration을 지원한다.
Broadcast Scan Method는 Linear Decompression의 특수한 경우로, Linear Decompressor가 fan-out wire만으로 구성된 degenerate case이다. Fan-out wire는 한 입력을 여러 출력으로 분기하는 단순한 연결선으로, XOR gate 없이 데이터를 복사하여 전달한다. 이는 Illinois scan의 Broadcast 모드와 유사하지만, 출력 공간(output space)이 제한적이고 선형 의존성(linear dependencies)이 많아 테스트 큐브를 인코딩할 확률이 Linear Decompressor에 비해 낮다. Linear Decompression은 LFSR과 Phase Shifter를 사용하여 더 다양한 출력 공간을 생성하며 LFSR의 크기가 테스트 큐브의 specified bit(지정된 비트) 개수보다 커야 한다.
Geometric method
Geometric Method는 칩 테스트에서 테스트 데이터를 압축하기 위해 lossless compression technique을 사용하는 기법이다. 테스트 벡터(test vectors)를 2D 행렬로 표현하고, 0과 1의 패턴을 기하학적 모양(point, line, triangle, rectangle)으로 덮어 데이터를 압축한다.
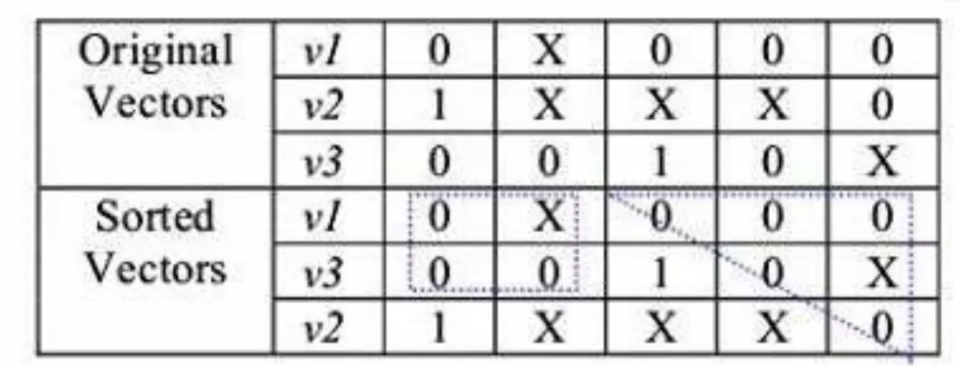
알고리즘은 다음과 같다. 먼저, 랜덤 test vector를 시작점으로 선택한다. 다음으로, 다른 테스트 벡터들을 첫 번째 벡터와의 correlation(상관관계)으로 정렬한다. 이미지에서 v1을 시작점으로 선택하고, v3와 v2를 v1과의 상관관계로 정렬하여 Sorted Vectors를 만든다. 상관관계는 벡터 간 유사성을 측정하는 것으로, v1과 v3는 첫 번째 비트가 0으로 동일하고 세 번째 비트가 0과 1로 다르지만, v1과 v2는 첫 번째 비트가 0과 1로 달라 v3가 v1에 더 가깝다. 정렬된 벡터는 0과 1의 패턴이 더 규칙적으로 배치되어 기하학적 모양으로 덮기 쉬워진다.
정렬된 테스트 벡터(Sorted Vectors)를 2D 행렬로 표현한 후, shape covering algorithm(모양으로 데이터를 덮는 알고리즘)을 사용하여 0이나 1의 그룹을 기하학적 모양(point, line, triangle, rectangle)으로 덮는다.
첫 번째 열(0, 0, 1)을 보면 0이 두 개 연속되므로 line으로 덮고, 그 좌표(시작점 (0,0), 끝점 (1,0))를 저장한다. 세 번째 열(0, 1, X)에서 0과 1이 섞여 있으므로, 0은 point(점)으로 덮고 좌표 (0,2)를 저장하며, 1은 point로 좌표 (1,2)를 저장한다. X는 don’t care bit이므로 0이나 1로 설정하여 패턴을 단순화한다. 최적의 covering shapes(덮는 모양)를 선택한 후, 이 정보를 인코딩하여 압축한다. 인코딩된 데이터는 모양의 종류와 좌표로 구성되며, ATE에 저장된다. Geometric Method는 Broadcast Scan Method와 달리, don’t care bits를 활용하여 데이터를 broadcasting하는 대신, 2D 패턴을 기하학적으로 압축한다. Geometric Method는 테스트 데이터의 압축률을 높이고 ATE의 메모리 사용량을 줄이는 데 유용하지만, 불규칙한 결함(RPR Faults)을 검출하기 어려울 수 있다.