5. BIRA Algorithms Using Hardware
External ATE(자동 테스트 장비)는 SOC(System on Chip) 내의 embedded memories에 쉽게 접근할 수 없다. 대신, SOC 메모리는 BISR(Built-In Self-Repair)을 통해 수리되며 BISR은 BIST(Built-In Self-Test)와 BIRA(Built-In Redundancy Analysis)를 결합한 방식이다. BISR은 추가적인 하드웨어를 필요로 하므로 BIRA 알고리즘은 external ATE에서 소프트웨어로 동작하는 RA 알고리즘보다 더 큰 area overhead를 요구한다.
5.1 BIRA Algorithms with Non-Optimal Repair Rate
Non-optimal repair rate를 가진 BIRA 알고리즘은 area overhead와 analysis speed를 우선시하며 repair rate를 희생한다.
5.1.1 LRM Algorithms
LRM(Local Repair-Most) 알고리즘은 local bitmap을 사용하며 hybrid RA 접근법을 채택한다. fault bitmap의 크기를 대폭 줄여 BIRA가 RM 알고리즘을 채택할 수 있게 한다. LRM은 BIST 동작과 동시에 spares를 적절히 할당하며 local bitmap은 row와 column address tags 및 m × n flags로 구성된다. row 0부터 가로로 fault cell을 detection해 나간다. 이 과정을 반복하면서 그 주소를 address tag에 저장한다. 만약 local bitmap을 초과한다면 LRM은 local bitmap에서 가장 많은 fault cell을 가진 line을 repair하고 그 line을 local bitmap에서 제거한다. faulty cell이 더 이상 감지되지 않거나 row/column address tags가 모두 채워질 때까지 실행된다. Bitmap 크기를 줄임으로써 area overhead가 크게 감소하지만 RA 과정에서 faulty cell 정보가 손실될 수 있어 optimal repair rate를 보장할 수 없다.
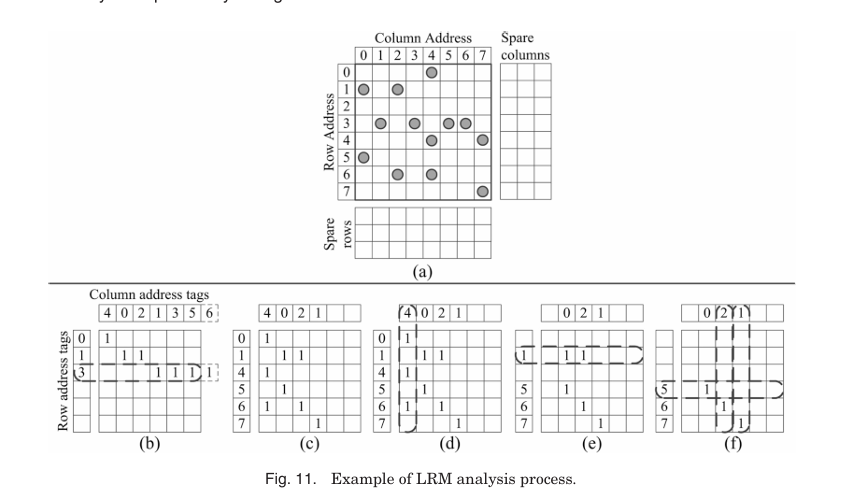
Figure 11(b)는 local bitmap에 6개의 faulty cells [(0, 4), (1, 0), (1, 2), (3, 1), (3, 3), (3, 5)]가 저장된 상태다. Faulty cell (3, 6)이 추가로 감지되지만 local bitmap에 저장할 공간이 없으므로 row address 3(가장 많은 faulty cell 보유)이 spare row로 수리되고 해당 항목이 지워진다. 이후 남은 faulty cell 정보가 저장된다(Figure 11(c)). Figure 11(d)에서는 column address 4가 가장 많은 faulty cells를 가지므로 수리되고 항목이 지워진다. Figure 11(e)는 column address 4 수리 후 상태를 보여주며, 3개의 faulty columns가 남아 있지만 row-first 전략에 따라 row address 1이 먼저 수리된다. 남은 3개의 single-fault cells는 충분한 spares로 수리된다. 최종 repair solution은 R(3, 1, 5)와 C(4, 2, 1)이다.
5.1.2 ESP Algorithm
BIRA에서 area overhead는 repair rate만큼 중요하다. ESP(Essential Spare Pivoting) 알고리즘은 dynamic RA 접근법을 사용하며 bitmap 대신 repair registers를 활용한다. Faulty line의 faulty cells 수가 threshold에 도달하면 essential pivot line으로 지정되어 반드시 수리된다. Threshold가 2로 설정되면, 2개 이상의 faulty cell를 포함한 faulty line이 essential pivot line이 된다. 새로 감지된 faulty cell이 기존 faulty cell과 동일한 row나 column 주소를 가지면 두 cell은 단일 spare line으로 수리된다. Spare row와 column의 합은 faulty memory 수리에 필요한 최소 저장 공간을 지정한다. ESP는 모든 faulty cell 정보를 저장하지 못해 repair rate가 optimal하지 않다.
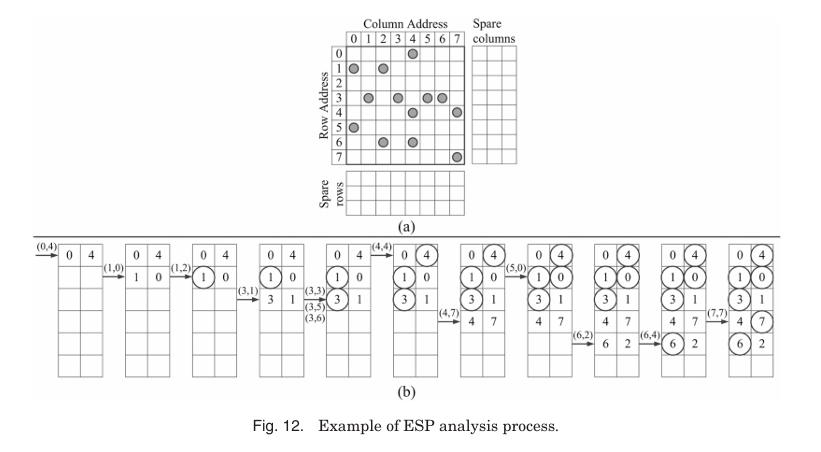
Figure 12를 보면 Spares 합이 6이므로 6개의 repair registers가 사용된다. 항상 row 0부터 봐보자. 첫 faulty cell (0, 4)의 주소가 첫 번째 repair register에 저장된다. 두 번째 faulty cell (1, 0)은 (0, 4)와 직교하므로 두 번째 repair register에 저장된다. 세 번째 faulty cell (1, 2)의 row 주소는 두 번째 register에 이미 저장되어 있어 row 1이 essential pivot row로 수리된다. 네 번째 faulty cell (3, 1)은 세 번째 register에 저장되고, 다섯 번째 faulty cell (3, 3)은 row 3을 essential pivot row로 만든다. Row 3 수리로 (3, 5), (3, 6)도 자동 수리된다. 여덟 번째 faulty cell (4, 4)로 column 4가 essential pivot column으로 수리된다. 이 과정은 반복되며, 최종 repair solution은 R(1, 3, 6)와 C(4, 0, 7)이다.
5.2 BIRA Algorithms with Optimal Repair Rate
Optimal repair rate를 보장하는 BIRA(Built-In Redundancy Analysis) 알고리즘은 메모리 수리의 정확성을 극대화하며 exhaustive search를 통해 모든 가능한 수리 방안을 탐색한다.
5.2.1 CRESTA Algorithm
CRESTA(Comprehensive Real-time Exhaustive Search and Test Analysis)는 analysis speed를 극대화하는 데 목표를 둔다. 복수의 sub-analyzers를 사용해 faulty memory를 수리하며 최대 장점은 analysis time이 사실상 0이라는 점이다. CRESTA는 dynamic RA 접근법을 채택하며 memory test 중 실시간으로 fault 정보를 분석한다.
exhaustive searching을 하고 모든 sub-analyzers가 서로 다른 spare row(Rs)와 spare column(Cs)의 조합을 병렬적으로 탐색한다. 각 sub-analyzer는 미리 정해진 할당 순서에 따라 spare line를 배치하며 모든 가능한 repair solution를 찾아내기 때문에 optimal repair rate를 보장한다.
하지만 Spare rows와 columns 수가 증가할수록 필요한 sub-analyzer 수가 기하급수적으로 늘어나 현실적으로 구현이 어려워진다. 필요한 sub-analyzers 수는 다음 조합 식으로 계산된다
Rs=3, Cs=3이면 (3+3)! / (3! × 3!) = 6! / (6 × 6) = 720 / 36 = 20개의 sub-analyzers가 필요하다.
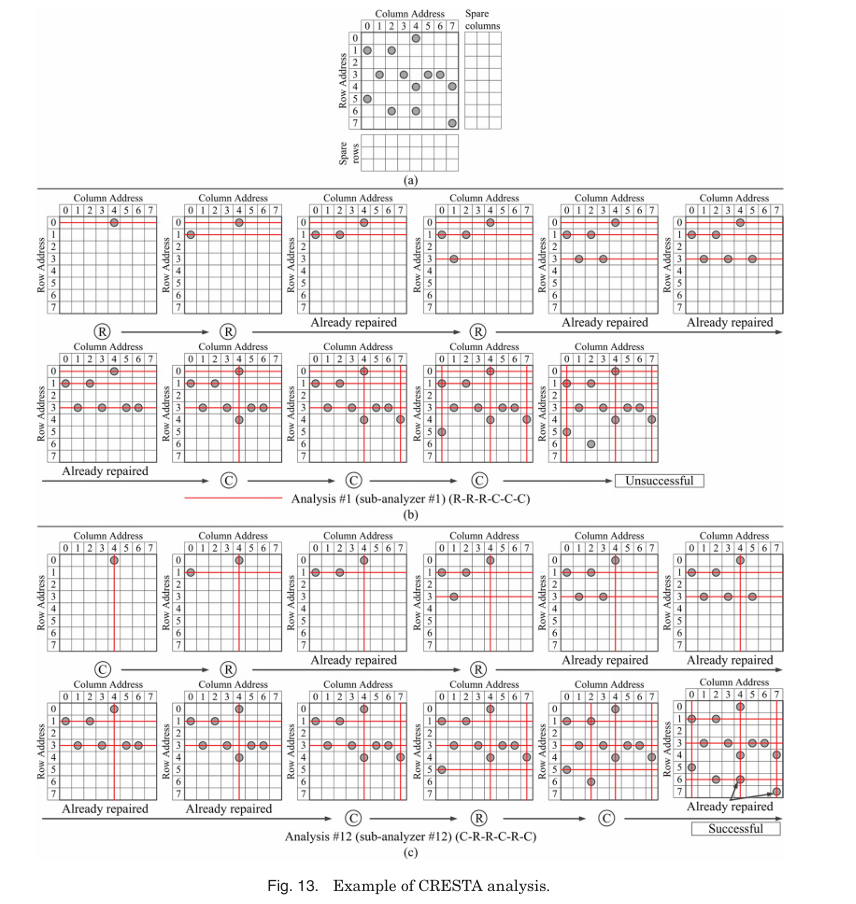
Figure 13(a)는 Rs=3, Cs=3인 faulty memory를 나타내며 총 13개의 faulty cells가 있다. Figure 13(b)와 (c)는 20개 sub-analyzers 중 2개(RRRCCC와 CRRCRC)의 solution 탐색 과정을 보여준다. 여기서 RRRCCC는 세 개의 row와 세 개의 column을 순서대로 할당하는 sub-analyzer #1을, CRRCRC는 column-row-row-column-row-column 순서의 sub-analyzer #12를 의미한다.
결과적으로 CRRCRC는 R(1, 3, 5)와 C(4, 7, 2)를 repair solution으로 도출한다. CRESTA는 빠른 분석 속도를 제공하지만 sub-analyzers의 수가 많아질수록 area overhead가 비현실적으로 커진다.
5.2.2 Intelligent Solve (IS) Algorithm
IS(Intelligent Solve) 알고리즘은 위의 문제를 해결하기 위해 depth-first traversal binary search tree를 사용하며 optimal repair rate와 area overhead 감소를 동시에 추구한다. Hybrid RA 접근법을 기반으로 하며 하드웨어는 stack에 쉽게 구현된다. BIST가 faulty cell을 감지하면 stack에 새 branch를 추가하고 첫 번째 사용 가능한 spare row나 column counter의 주소를 재계산한다. Spare row와 column의 할당 순서는 memory test 전에 미리 정의되며 탐색이 실패하면 row나 column counter를 줄여 backtracking을 시작한다. binary search tree를 올라가며 다른 branch를 탐색한다.
IS는 must-repair analysis와 dynamic must-repair analysis로 search space를 줄인다. 먼저 must-repair line을 spare line으로 대체하고 남은 faulty cells를 분석한다. 새 repair 단계에서 stack에 branch가 추가될 때마다 available spare 수가 변동하며 dynamic must-repair analysis가 실행된다. 이는 탐색 공간과 solution 찾는 시간을 줄인다. ISF(IS의 변형)는 첫 번째 solution을 찾으면 탐색을 중단해 backtracking과 search time을 더욱 단축한다.
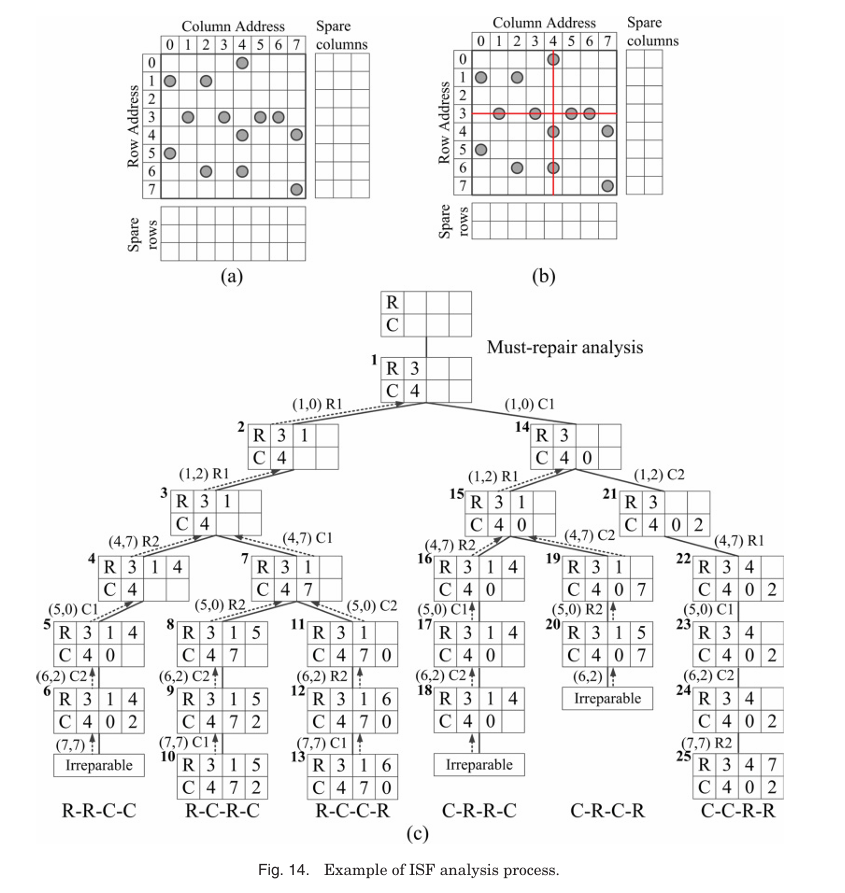
Figure 14(a)는 faulty memory를 Figure 14(b)는 must-repair line인 row address 3과 column address 4가 수리된 상태를 나타낸다. Figure 14(c)는 depth-first tree traversal 과정을 상세히 보여준다
1. Root node: Stack에 푸시된다.
2. R-R-C-C branch: (1, 0)에 R1, (4, 7)에 R4, (5, 0)에 C0, (6, 2)에 C2를 할당하지만 (7, 7)이 남아 실패한다. (Depth First Search)
3. Backtracking: Node 3에서 R-C-R-C branch로 전환(Depth First Search) R1, C4, R5, C2로 모든 faulty cells를 수리하며 node 10에서 성공.
4. R-C-C-R, C-C-R-R도 가능하지만 ISF는 node 10에서 종료한다.
최종 repair solution은 node 10의 R(1, 5)와 C(7, 2)다. IS는 CRESTA보다 area overhead가 작지만 backtracking으로 인해 analysis speed가 느리다.
5.4. Dynamic Random Access Memory (DRAM) Repair Techniques
다. DRAM은 데이터를 유지하려면 일정 주기로 refresh되어야 한다. 이는 데이터가 시간이 지나면서 leakage로 인해 사라지기 때문이다. 하지만 retention failures는 DRAM cells가 refresh 전에 데이터를 잃을 때 발생한다. DRAM에서는 retention failures로 인해 이 문제가 더 심각하고 따라서 DRAM reliability는 많은 연구의 초점이 되었다.
5.4.1. Retention-Aware Intelligent DRAM Refresh (RAIDR)
refresh operations는 데이터 보존에 필수적이지만 memory throughput을 줄이고 memory latency를 증가시킨다. RAIDR(Retention-Aware Intelligent DRAM Refresh)은 memory controller의 overhead를 최소화하면서 DRAM 칩의 refresh operation 수를 줄일 수 있다. 많은 refresh operation는 불필요한데 refresh rate가 보통 device 내 가장 약한 cell을 기준으로 설정되기 때문이다. 그래서 대부분의 DRAM cells는 data retention time(데이터 유지 시간)이 만료되기 전에 refresh된다. RAIDR은 row line을 retention time에 따라 분류하고 각 범주에 다른 refresh rate를 지정한다. 여기서 row의 retention time은 해당 row에서 가장 leakage가 심한 cell의 retention time으로 정의된다.
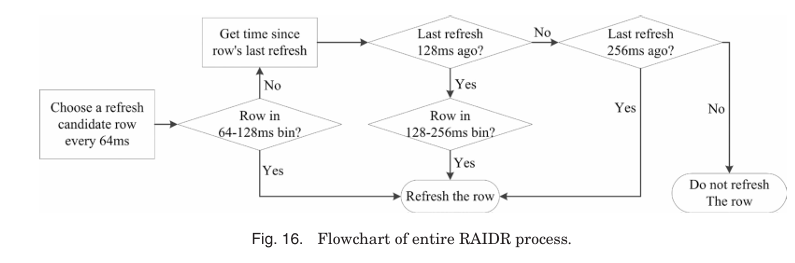
먼저 retention time profiling을 통해 각 row의 retention time을 확인한다. 그 후 memory controller는 row를 retention time bin으로 분류한다. 마지막으로 refresh candidate가 선택될 때마다 refresh operations를 실행한다. Figure 16에서는 row가 두 개의 retention time bin에 저장된다. 데이터 무결성을 보장하기 위해 첫 번째 bin은 64ms, 두 번째 bin은 128ms 간격으로 refresh된다. 최단 retention time이 bin 내 모든 row에 도달하지 못하면 새로운 default refresh interval이 생성된다. profiling 후 memory controller는 rows를 적절한 bin에 넣고, 각 bin에 다른 refresh rate를 할당한다. refresh timing은 64ms 간격의 배수로 계산되므로 간단히 결정된다.
5.4.2. ArchShield
기존 DRAM repair 기법은 높은 error rate를 견디는 데 한계가 있다. ArchShield는 faulty cell 정보를 architectural level에서 노출시켜 높은 error-rate 상황에서 DRAM 칩의 tolerance를 높인다. ArchShield의 주요 구성 요소는 fault map과 selective word level replication(SWLR)이다. fault map은 word line의 faulty cell 수를 저장한다. SWLR은 적어도 하나의 faulty cell이 있는 모든 words를 복제한다. word에 여러 faulty cells가 있으면 ArchShield는 원래 word line을 복제본으로 교체한다. 그렇지 않고 하나의 faulty cell만 있다면 이 cell이 reparable인지 확인한다. one-bit soft error나 irreparable error로 판결되면 word는 복제본으로 교체된다. performance overhead를 줄이기 위해 fault map은 last level cache(LLC)를 통해 접근된다.
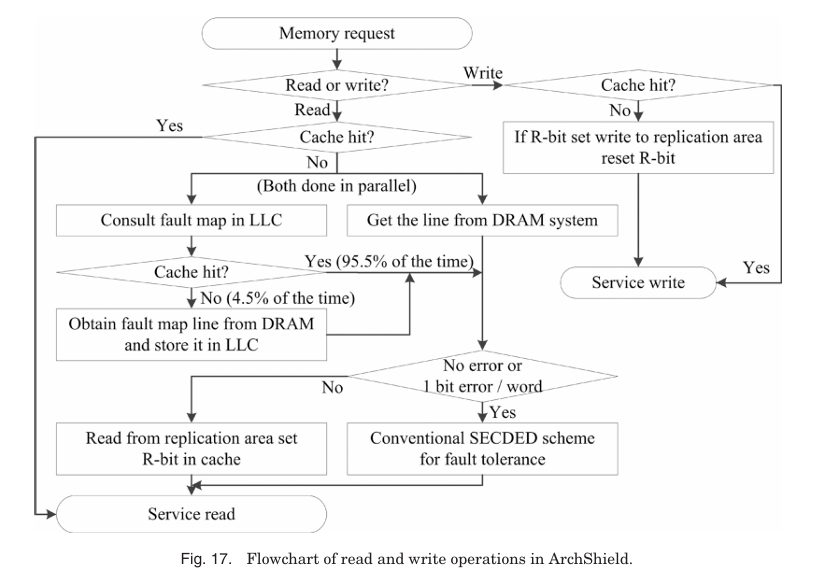
cache request가 "miss"일 때 read signal이 memory로 전달되고 LLC에서 fault map address를 참조하며 fault map entry가 계산된다. LLC hit이 발생하면 fault map entry가 검색되고 아니면 추가 read signal이 memory로 전송된다. 복제 영역은 multiple error나 one-bit irreparable error가 있을 때만 읽힌다. 이 과정에서 replication bit(R-bit)이 추가되어 row line이 복제본으로 교체될 필요가 있는지 확인한다.