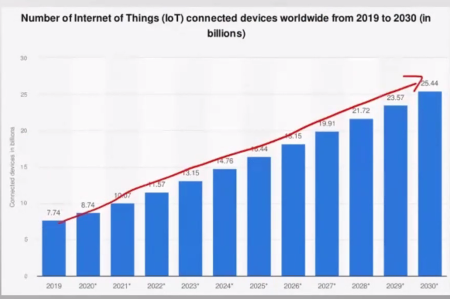
1. TD Learning (Temporal Difference Learning)PurposeTD Learning은 상태 가치 함수 V(s)를 학습정책 π를 따를 때, 상태 s에서 시작하여 기대할 수 있는 expected cumulative reward을 평가하는 데 사용ElementsState (s)현재 에이전트가 위치한 상태.틱택토 게임에서 현재 보드 상태.Value Function (V(s))상태 s의 가치상태 s에서 시작해 정책 π를 따를 때 기대되는 미래 누적 보상V(s) = E_pi[sum_{t=0~infinity} gamma^t * r_t | s_0 = s]E_pi : 기대값 (Expectation under policy), 정책 π를 따를 때 발생할 수 있는 모든 가능한 결과(보상)의 평균..