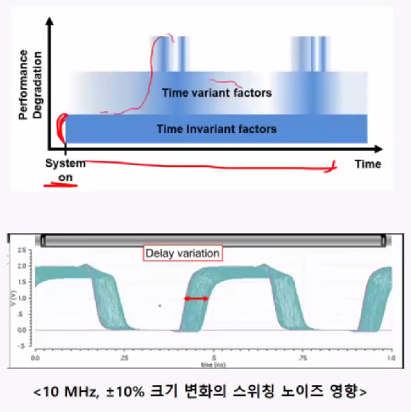
특성 변화 원인시변(Time Variant)특성 변화스위칭 노이즈에 의한 공급전압, 바이어스 전압 변화온도 변화시불변(Time Invariant) 특성 변화공정(process) 산포에 의한 W, L, Vth등의 변화공급전압 및 바이어스 전압 오차문제점아날로그 회로의 경우 전압 이득, 대역폭 등을 변화시킴디지털 회로의 경우 타이밍에 변화를 주어 셋업 홀드 마진에 악영향 메모리인터페이스의 트레이닝전압 및 타이밍 마진 확보를 위한 다양한 트레이닝을 지원함Command/Address 트레이닝Command Bus TraningWrite Margin 트레이닝WCK2CK levelingWrite Data TrainingWCK Duty Cycle TrainingRead Margin 트레이닝Read Gate Traini..