데이터 전 처리
- 머신러닝을 통해 최적화하고자하는 Input Parameter를 변수로 하여 split하여 엑셀 파일에 저장
- Ex) PMOS Width = 1E-6 ~ 1E-5
- Input data와 종속변수 Output Data를 각각 datas.xlsx파일과 target.xlsx파일을 만들어 저장(좌측이 datas, 우측이 target)


Colab에서 files.upload()함수를 사용하여 두 파일을 업로드

- X에 입력 데이터, Y에 출력 데이터를 넣고 0과 1사이로 정규화 함.
- 훈련 데이터는 80퍼, 테스트 데이터는 20퍼로 놓고 테스트 데이터를 검증 데이터와 테스트 데이터로 분할

- 첫 번째 은닉층은 100개의 뉴런과 ReLU 활성화 함수, 입력 크기는 1.
- 이후 추가 레이어는 각각 150개, 100개의 뉴런을 사용
- 마지막 레이어는 2개의 출력 노드를 가지며, Rising_Time과 Falling_Time을 예측

- 훈련 손실과 검증 손실을 그래프로 시각화
- 테스트 데이터를 사용해 예측값을 생성하고, 실제값과 예측값을 분리

- 평균제곱오차(MSE), 평균제곱근오차(RMSE), 로그 스케일 평균제곱오차(RMSLE)를 계산
- X축(P_Width)과 Y축(실제값 및 예측값)을 설정
- 예측된 Rising_Time과 실제값을 비교하는 산포도를 생성
- 예측된 Falling_Time과 실제값을 비교하는 산포도를 생성

실제값과 예측값 간의 관계를 시각화하여 예측 오차를 확인
실행 결과
Epoch 150까지의 실행 과정이 보이고나서 그래프들이 출력된다

- Model loss는 모델의 예측값(Predict data)과 실제값(Test data) 사이의 차이를 나타내는 지표이다. train loss는 훈련 데이터에 대한 모델의 오차이고 test loss는 모델이 학습하지 않은 새로운 데이터(test data)에 대한 오차이다.
- 일반적으로 train loss와 test loss는 비슷해야하며 train loss가 낮고 test loss가 높다면 과적합(overfitting)이 발생했을 가능성이 있고 반대로 둘 다 높으면 모델이 충분히 학습되지않은 상태(underfitting)일 수 있다.
- 과적합을 방지하기 위해 Dropout과 정규화 기법을 사용할 수 있다.
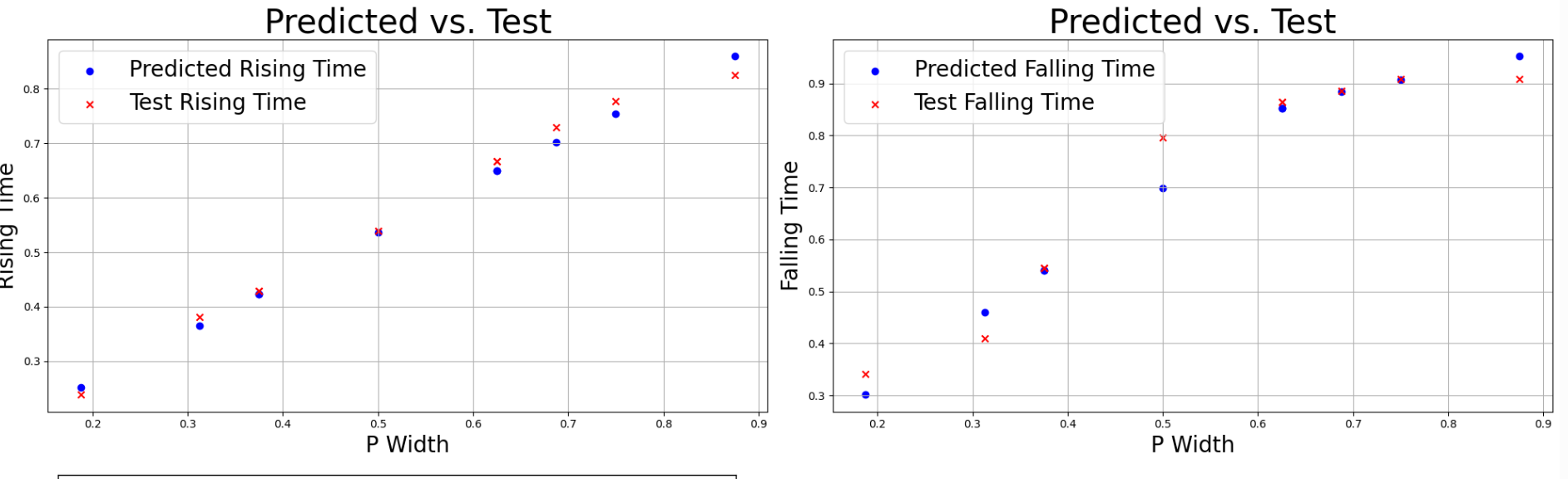
- 위는 Rising_Time과 Falling Time의 모델 예측값(Predict data)과 실제값(Test data) 사이의 차이는 모델이 새로운 데이터에 대해 얼마나 잘 일반화하고 있는지를 보여준다.
- 차이가 작을수록 모델이 정확히 예측
- 평가 지표는 Mean Squared Error(MSE, 평균 제곱 오차이므로 큰 크기에 민감), Mean Absolute Error(MAE, 오차의 절대값의 평균이므로 그대로 반영) 등이 사용
'AI System Semiconductor' 카테고리의 다른 글
| 11.1 Hardware Security IP (0) | 2025.01.10 |
|---|---|
| 10.1. AI 가속기 설계 기술 (0) | 2025.01.09 |
| 9.2. DRAM Sense amplifier (0) | 2025.01.09 |
| 9.1. 저전력 고속 메모리 설계(CMOS 인버터) (0) | 2025.01.09 |
| 8.4. 주요 동작 특성 트레이닝 (0) | 2025.01.09 |