AI 연산의 가속 방법
- 곱셈-누적(Multiply and Accumulate, MAC)연산
- MAC 연산은 뉴런의 가중치와 입력값을 곱하고 그 결과를 누적하는 과적을 반복함(이는 신경망의 모든 계층에서 반복)
- MAC 연산이 걸리는 시간이 추론 속도를 크게 좌우함.
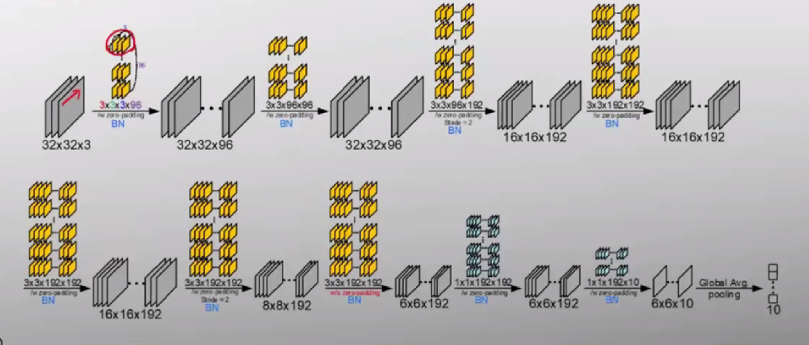
MAC연산의 가속
1) 전용 벡터 유닝 프로세싱 유닛이나 텐서 가속 유닛과 같은 하드웨어 모듈을 칩 상에 대량 집적하는 방식
- 연산유닛의 대량 집적은 MAC 연산을 병렬로 수행할 수 있게하여 연산 속도를 극대화함.
- 밑의 NVIDIA의 GPU 아키텍처는 매트릭스 연산에 특화된 구조로, 대규모 MAC 연산을 빠르게 수행할 수 있도록 설계

2) 데이터 재사용과 메모리 접근 효율을 극대화하는 방식
- MAC연산의 성능은 데이터 이동속도에도 크게 영향
- 입력 데이터 가중치를 ㅈ최대한 재사용하고 데이터 이동에 필요한 에너지 최소화
3) In-Memory Computing
- 메모리 안에서 직접 연산을 수행
- 데이터가 저장된 메모리 셀 자체에서 MAC 연산을 수행-> 메모리 대역폭을 효과적으로 활용

AI 가속기 설계
- NPU의 주요 목적은 병렬 처리를 통해 딥러닝 모델 학습과 추론 시간을 크게 향상시키는것
- NPU 아키텍처는 아래 모듈들을 병렬적으로 두어 연산을 빠르게 처리
- PE : 행렬의 연산에 필요한 MAC 연산 수행
- 비선형 함수 계산: ReLU, Sigmoid, tanh 등의 비선형 함수 연산 수행
- 데이터 전송 병목 현상을 위해 PE 간의 데이터 전송 및 외부 메모리로의 read/write를 최소화

- 데이터의 Sparsity에 따라서 sparse하지 않은 데이터는 raw 데이터로, sparse 한 데이터는 RLC(Run Length Coding)를 활용하여 압축된 형식으로 다뤄 데이터 전송의 효율성을 향상
- 기존 양자화 방법들이 하드웨어의 복잡성을 증가시키는 문제를 해결하기 위해 8비트까지 scalable한 계층적 디코딩 구조 제안
아날로그 기반 인메모리 컴퓨팅 VS 디지털 기반 인-메모리 컴퓨팅

아날로그 기반
- 전압,전류 등의 아날로그 신호를 활용하여 MAC 연산을 수행
- 입력 데이터를 Digital-to-Analog Converter(DAC)를 거쳐 전류나 전압으로 변환하고, SRAM 셀에서 아날로그 방식으로 MAC 연산을 수행한 뒤, Analog-to-Digital Converter(ADC)를 거쳐 MAC 연산 결과를 디지털화함.
디지털 기반
- 신호를 아날로그 값으로 변환하지 않기때문에 ADC와 DAC가 필요하지 않음
- SRAM과 함께 AND, OR, XOR 등의 논리 게이트와 덧셈기 등을 활용하여 MAC 연산을 구현
'AI System Semiconductor' 카테고리의 다른 글
| 12.2 Security Chip 주요 요소 기술 (0) | 2025.01.10 |
|---|---|
| 11.1 Hardware Security IP (0) | 2025.01.10 |
| 9.3. Deep Learning Optimization 실습 (0) | 2025.01.09 |
| 9.2. DRAM Sense amplifier (0) | 2025.01.09 |
| 9.1. 저전력 고속 메모리 설계(CMOS 인버터) (0) | 2025.01.09 |